Ingest data from csv file and apply vector embeddings using custom python processor
This article is a part of Vector Search using Spring AI Elastic Search and Apache Nifi 2
Let's create a simple python processor to ti pull data from csv file. Instead of search and querying data on the fly we will import a csv file which can be downloaded from here
Preview of csv Data, I have removed a couple of commands and row just o preview data here.
| title | brand | initial_price | final_price | currency | availability | reviews_count | asin |
|---|---|---|---|---|---|---|---|
| Saucony Men's Kinvara 13 Running Shoe | Saucony | null | "57.79" | USD | In Stock | 702 | B09NQJFRW6 |
| KASOTT Replacement Airpod Pro Ear Tip Premium Memory Foam Earbud Tips, Perfect Noise Reduction, Ultra-Comfort, Anti-Slip Eartips, Fit in The Charging Case (Sizes M, 3 Pairs) | KASOTT | "17.88" | "17.88" | USD | In Stock | 67 | B0BGSF52LR |
| Bio-Oil Skincare Body Oil (Natural) Serum for Scars and Stretchmarks, Face and Body Moisturizer Hydrates Skin, with Organic Jojoba Oil and Vitamin E, For All Skin Types, 6.7 oz | Bio-Oil | "39.24" | "24.95" | USD | In Stock | 6095 | B08XMPKJ1L |
| crysting 13 Inch Sewing Box Three Layers, Plastic Craft Organizers and Storage, Multifunction Craft Box/Organizer Box/First Aid Box/Medicine Box/Tool Organizers and Storage with Lids | crysting | "22.99" | "20.99" | USD | In Stock | 210 | B0B8CP57MN |
| Ridgid 62990 T-201 5" Straight Auger | RIDGID | "27.38" | "25.38" | USD | Only 5 left in stock - order soon | 28 | B001HWGJAK |
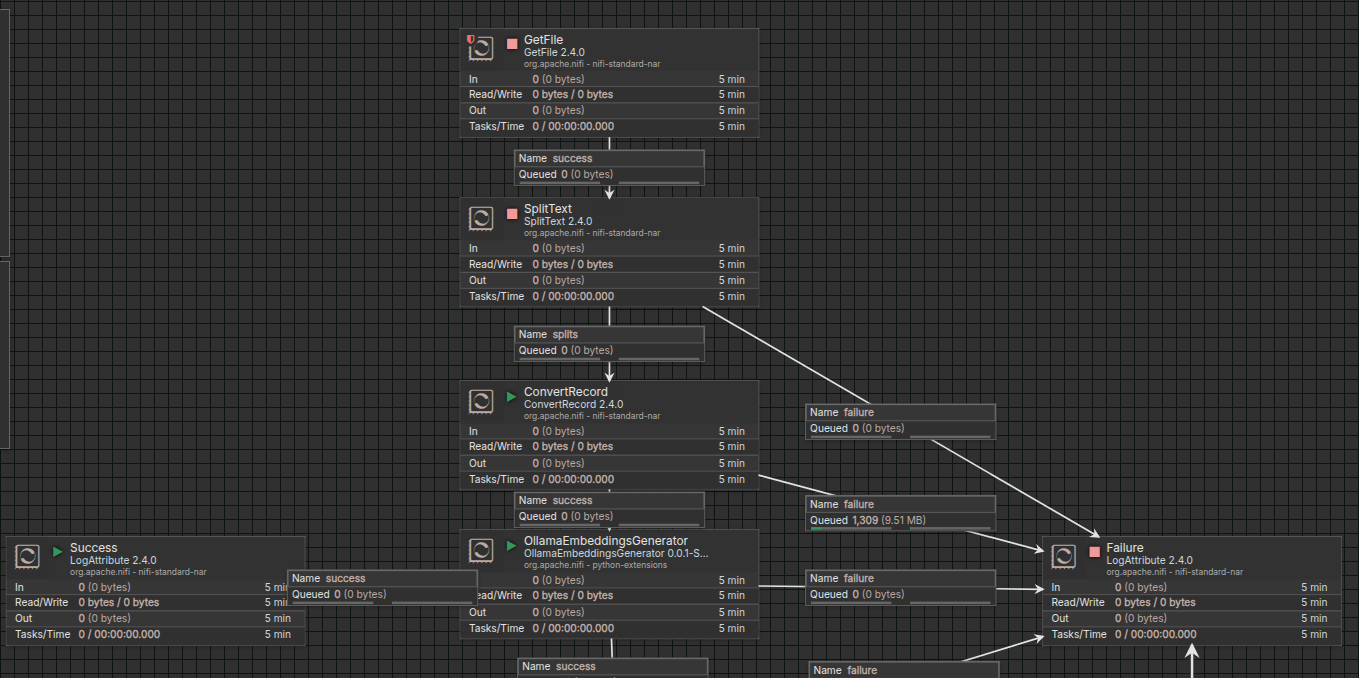
Following is the Apache Nifi Flow to inget and transform data
Here I am doing following things to preprocess data for vector search
- Read csv file using
GetFileprocessor - Split csv into separate chunks using
SplitTextprocessor - Then I transform this csv line in to json format using
ConvertRecordprocessor
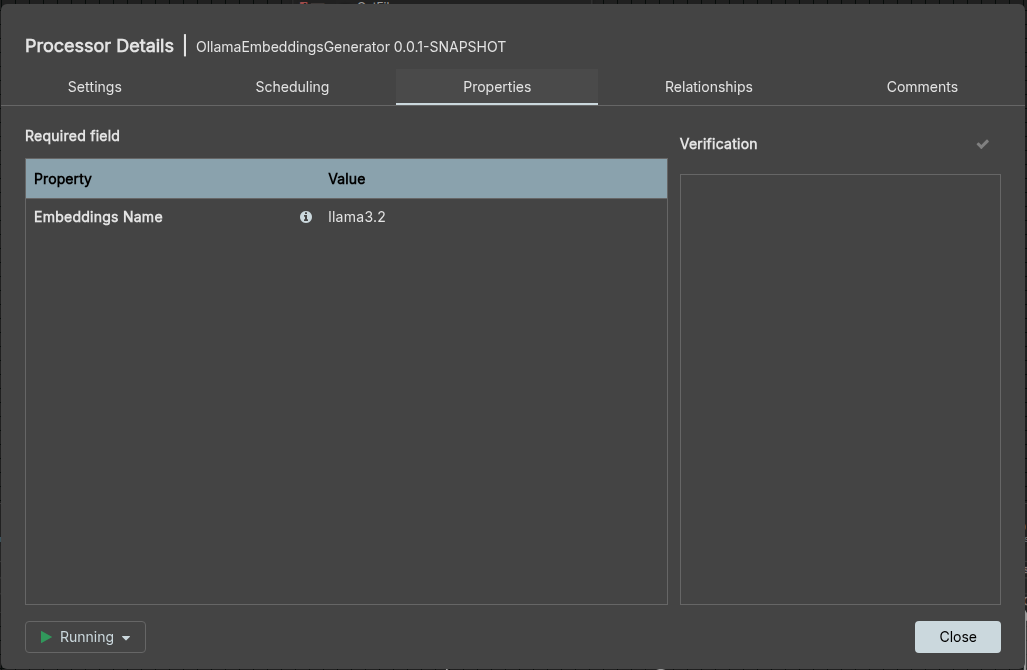
Once all these steps are complete i feed it to custom processor which i create using python extensions called OllamaEmbeddingsGenerator
Here is the code for OllamaEmbeddingsGenerato Processor
1import datetime
2import hashlib
3import json
4
5import ollama
6import pytz
7
8from nifiapi.flowfiletransform import FlowFileTransform, FlowFileTransformResult
9from nifiapi.properties import PropertyDescriptor, StandardValidators
10
11
12class OllamaEmbeddingsGenerator(FlowFileTransform):
13 class Java:
14 implements = ['org.apache.nifi.python.processor.FlowFileTransform']
15
16 class ProcessorDetails:
17 version = '0.0.1-SNAPSHOT'
18 dependencies = ['ollama', 'pytz']
19
20 def __init__(self, **kwargs):
21 super().__init__()
22 options = [
23 "llama3.2",
24 "nomic-embed-text",
25 "granite-embedding",
26 "snowflake-arctic-embed2",
27 "all-minilm"
28 ]
29 self.embeddings = PropertyDescriptor(name="Embeddings Name",
30 description="Name of the embeddings Model",
31 required=True,
32 allowable_values=options,
33 validators=[StandardValidators.NON_EMPTY_VALIDATOR])
34 self.descriptors = [self.embeddings]
35
36 def getPropertyDescriptors(self):
37 return self.descriptors
38
39 def transform(self, context, flowfile):
40 flow_file_content = flowfile.getContentsAsBytes().decode('utf-8', "ignore")
41 json_content = json.loads(flow_file_content)
42 title = json_content['title']
43 brand = json_content['brand']
44 embeddings_name = context.getProperty(self.embeddings.name).getValue()
45 self.logger.info(f"Generating Ollama Embeddings Using {embeddings_name} model")
46 self.logger.info(f"Embedding Text {title} and {brand}")
47 input_text = f"Title: {title}, Brand Name: {brand}"
48 json_content['text'] = input_text
49 json_content['content'] = input_text
50 json_content['metadata'] = {}
51 json_content['embedding'] = self.__get_ollama_embeddings(embeddings_name, input_text)
52 md5hash = hashlib.md5(json_content['asin'].encode('utf-8')).hexdigest()
53 json_content['id'] = md5hash
54 json_content['@@timestamp'] = datetime.datetime.now(pytz.timezone('UTC')).isoformat()
55
56 return FlowFileTransformResult(relationship="success", contents=json.dumps(json_content),
57 attributes=flowfile.getAttributes())
58
59 def __get_ollama_embeddings(self, embeddings_name: str, input_text: str):
60 ollama_response = ollama.embed(model=embeddings_name, input=input_text)
61 self.logger.info(f"Embeddings Text::::: length {len(ollama_response['embeddings'])}")
62 return ollama_response['embeddings'][0]
Embeddings
If you closely examine python code line
1json_content['embedding'] = self.__get_ollama_embeddings(embeddings_name, input_text)
I am modifying the flow file content to add additional attribute to the json element this is the embedding vector created using on of these models.
1options = [
2 "llama3.2",
3 "nomic-embed-text",
4 "granite-embedding",
5 "snowflake-arctic-embed2",
6 "all-minilm"
7]
To read more about Ollama and its Models please visit this page
Apache Nifi 2 Processor Diagram
Main Flow
OllamaEmbeddingsGenerator
In the next article we see how this json we dump in elastic search using Apache Nifi 2