Supervised Learning Thera Bank case study
Overview
The classification goal is to predict the likelihood of a liability customer buying personal loans.
Solution
1#Import Necessary Libraries
2
3# NumPy: For mathematical funcations, array, matrices operations
4import numpy as np
5
6# Graph: Plotting graphs and other visula tools
7import pandas as pd
8import seaborn as sns
9
10sns.set_palette("muted")
11
12# color_palette = sns.color_palette()
13# To enable inline plotting graphs
14import matplotlib.pyplot as plt
15%matplotlib inline
1# Import CSV data using pandas data frame
2df_original = pd.read_csv('bank.csv')
3
4# Prepare columns names
5df_columns = []
6for column in df_original.columns:
7 df_columns.append(column)
8
9# Prepare mapping of column names for quick access
10df_columns_map = {}
11map_index: int = 0
12for column in df_columns:
13 df_columns_map[map_index] = column
14 map_index = map_index + 1
15
16print("Columns {}".format(df_columns))
17print("***********************************************************************************************************************")
18print("Columns Map {}".format(df_columns_map))
19
20# We have separated out columns and its mapping from data, at any point of time during data analysis or cleaning we
21# can directly refer or get data from either index or column identifier
22
23# See data overview
24
25df_original.head()
Columns ['ID', 'Age', 'Experience', 'Income', 'ZIP Code', 'Family', 'CCAvg', 'Education', 'Mortgage', 'Personal Loan', 'Securities Account', 'CD Account', 'Online', 'CreditCard']
***********************************************************************************************************************
Columns Map {0: 'ID', 1: 'Age', 2: 'Experience', 3: 'Income', 4: 'ZIP Code', 5: 'Family', 6: 'CCAvg', 7: 'Education', 8: 'Mortgage', 9: 'Personal Loan', 10: 'Securities Account', 11: 'CD Account', 12: 'Online', 13: 'CreditCard'}
| ID | Age | Experience | Income | ZIP Code | Family | CCAvg | Education | Mortgage | Personal Loan | Securities Account | CD Account | Online | CreditCard | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 25 | 1 | 49 | 91107 | 4 | 1.6 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 2 | 45 | 19 | 34 | 90089 | 3 | 1.5 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2 | 3 | 39 | 15 | 11 | 94720 | 1 | 1.0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 4 | 35 | 9 | 100 | 94112 | 1 | 2.7 | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 5 | 35 | 8 | 45 | 91330 | 4 | 1.0 | 2 | 0 | 0 | 0 | 0 | 0 | 1 |
1# Lets analyse data based on following conditions
2# 1. Check whether all rows x colums are loaded as given in question, all data must match before we start to even operate on it.
3# 2. Print shape of the data
4# 8. Check data types of each field
5# 3. Find presence of null or missing values.
6# 4. Visually inspect data and check presense of Outliers if there are any and see are
7# they enough to drop or need to consider during model building
8# 5. Print shape of the data
9# 6. Do we need to consider all data columns given in data set for model building
10# 7. Find Corr, median, mean, std deviation, min, max for columns.
11
12# Below is info for our data
13
14df_original.info();
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5000 entries, 0 to 4999
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 5000 non-null int64
1 Age 5000 non-null int64
2 Experience 5000 non-null int64
3 Income 5000 non-null int64
4 ZIP Code 5000 non-null int64
5 Family 5000 non-null int64
6 CCAvg 5000 non-null float64
7 Education 5000 non-null int64
8 Mortgage 5000 non-null int64
9 Personal Loan 5000 non-null int64
10 Securities Account 5000 non-null int64
11 CD Account 5000 non-null int64
12 Online 5000 non-null int64
13 CreditCard 5000 non-null int64
dtypes: float64(1), int64(13)
memory usage: 547.0 KB
1# 1. Check whether all rows x colums are loaded as given in question, all data must match before we start to even operate on it.
2
3#df_original.describe() difficult to view hence lets apply transpose() to visually see it better
4
5df_original.describe().transpose()
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| ID | 5000.0 | 2500.500000 | 1443.520003 | 1.0 | 1250.75 | 2500.5 | 3750.25 | 5000.0 |
| Age | 5000.0 | 45.338400 | 11.463166 | 23.0 | 35.00 | 45.0 | 55.00 | 67.0 |
| Experience | 5000.0 | 20.104600 | 11.467954 | -3.0 | 10.00 | 20.0 | 30.00 | 43.0 |
| Income | 5000.0 | 73.774200 | 46.033729 | 8.0 | 39.00 | 64.0 | 98.00 | 224.0 |
| ZIP Code | 5000.0 | 93152.503000 | 2121.852197 | 9307.0 | 91911.00 | 93437.0 | 94608.00 | 96651.0 |
| Family | 5000.0 | 2.396400 | 1.147663 | 1.0 | 1.00 | 2.0 | 3.00 | 4.0 |
| CCAvg | 5000.0 | 1.937938 | 1.747659 | 0.0 | 0.70 | 1.5 | 2.50 | 10.0 |
| Education | 5000.0 | 1.881000 | 0.839869 | 1.0 | 1.00 | 2.0 | 3.00 | 3.0 |
| Mortgage | 5000.0 | 56.498800 | 101.713802 | 0.0 | 0.00 | 0.0 | 101.00 | 635.0 |
| Personal Loan | 5000.0 | 0.096000 | 0.294621 | 0.0 | 0.00 | 0.0 | 0.00 | 1.0 |
| Securities Account | 5000.0 | 0.104400 | 0.305809 | 0.0 | 0.00 | 0.0 | 0.00 | 1.0 |
| CD Account | 5000.0 | 0.060400 | 0.238250 | 0.0 | 0.00 | 0.0 | 0.00 | 1.0 |
| Online | 5000.0 | 0.596800 | 0.490589 | 0.0 | 0.00 | 1.0 | 1.00 | 1.0 |
| CreditCard | 5000.0 | 0.294000 | 0.455637 | 0.0 | 0.00 | 0.0 | 1.00 | 1.0 |
Data Analysis Column Wise
- ID: seems just a identity representation of row or an item in a data frame, this can be dropped when processing model.
- Age: based on std, q1, q2, q3 seems valid values.
- Experience: Look at min, it say -3 experience cannot be in negative and this particular needs correction. Ideal values should be 0-80 considering a person started to work at 20 years and lives for max 100 years.
- ZipCode: All values seems fine. If we wish to discard region from the model still our model is not impacted if we drop this column. But at later stage we are predicting, people from which area are accepting more personal loans, then we may need to consider this field mandatorily.
- Family: Data looks ok and can play role like if children are less, then less responsibility and hence no need of loan, but more kids and then sometime people tend to go for extra loan apart from education as well. So this is very important field in model buulding.
- CreditCard: General human assumption i would do that, person who has creditcard is vrey unlikely to go for personal load. But if the need arises for a longer term some data points might be there who has credit card as well as personal loan.
Skipping some other fields which are self explanatory.
1# From our given data set we have succesfully loaded all columns looking at the column labels
2# Lets check shape of the data
3df_original.shape
4
5# Here we see total 5000 rows and 14 colums.
(5000, 14)
1# sns.boxplot(y="Age", orient="v", x="Personal Loan", hue="Education", data=df_original)
1# Data types of fields
2
3df_original.dtypes
4
5# We see that everything is numeric data and need not need any conversion
ID int64
Age int64
Experience int64
Income int64
ZIP Code int64
Family int64
CCAvg float64
Education int64
Mortgage int64
Personal Loan int64
Securities Account int64
CD Account int64
Online int64
CreditCard int64
dtype: object
1# Presence of null values or missing values
2df_original.isnull().values.any()
3
4# This tell us that we have for each row x column.
False
Check validity for data, as we have seen, there is no missing data in out data frame, but are the values valid enough like we have seen that experience field has -3 having experience as -3 doesnt add any value to our model but it may impact our final consideration, this also depends on how many such values are present. Lets print column colmposition or categories spread of data for suspicious column.
1# Lets see what are experience range in our data set we have.
2
3print("Experience has unique data in this range {}".format(df_original["Experience"].unique().tolist()))
4
5# len(df_original[df_original["Experience"] < 0]['Experience'].unique().tolist())
6df_experience = df_original[df_original['Experience'] < 0]
7df_experience['Experience'].value_counts()
8
9# So there are 52 values whose experience is a missing value which constitute ~1 % of data for experience column
10# We have few options to deal with this
11# - purge this invalid data
12# - Replace it with meaning full
Experience has unique data in this range [1, 19, 15, 9, 8, 13, 27, 24, 10, 39, 5, 23, 32, 41, 30, 14, 18, 21, 28, 31, 11, 16, 20, 35, 6, 25, 7, 12, 26, 37, 17, 2, 36, 29, 3, 22, -1, 34, 0, 38, 40, 33, 4, -2, 42, -3, 43]
-1 33
-2 15
-3 4
Name: Experience, dtype: int64
1# Lets quickly check Age
2
3print("Age experience has unique data in this range {}".format(df_original['Age'].unique().tolist()))
4# This looks ok.
5
6#Values count
7df_original['Age'].value_counts()
8
9# There are no suspicious values
Age experience has unique data in this range [25, 45, 39, 35, 37, 53, 50, 34, 65, 29, 48, 59, 67, 60, 38, 42, 46, 55, 56, 57, 44, 36, 43, 40, 30, 31, 51, 32, 61, 41, 28, 49, 47, 62, 58, 54, 33, 27, 66, 24, 52, 26, 64, 63, 23]
35 151
43 149
52 145
58 143
54 143
50 138
41 136
30 136
56 135
34 134
39 133
59 132
57 132
51 129
60 127
45 127
46 127
42 126
40 125
31 125
55 125
62 123
29 123
61 122
44 121
32 120
33 120
48 118
38 115
49 115
47 113
53 112
63 108
36 107
37 106
28 103
27 91
65 80
64 78
26 78
25 53
24 28
66 24
23 12
67 12
Name: Age, dtype: int64
We are able to view visually since values are in thousands range what if it is lakhs. It is not feasible of even a good approach to manually check terminal and see if we have invalid values. In that case we can try to parse the values in fields. Create a helper method for string, bool, int and other data types. Signature might look like this:
1def all_int(self, column_int_values_list):
2 # Iterate over list parsing values
Lets try to check validity of values using parse approach.
1# Validate function
2
3def validate_column(column_as_list, column_name):
4 print("Analysing {} column for unique value {}".format(column_name, column_as_list))
5 for value in df_original['Age'].tolist():
6 try:
7 value += 1
8 except TypeError:
9 print("Error identyfying {} in {} column ".format(value, column_name) )
10 return False
11 return True
12
1print("Is Age column valid {}".format(validate_column(df_original['Age'].unique().tolist(), 'Age')))
Analysing Age column for unique value [25, 45, 39, 35, 37, 53, 50, 34, 65, 29, 48, 59, 67, 60, 38, 42, 46, 55, 56, 57, 44, 36, 43, 40, 30, 31, 51, 32, 61, 41, 28, 49, 47, 62, 58, 54, 33, 27, 66, 24, 52, 26, 64, 63, 23]
Is Age column valid True
1print("Is Experience column valid {}".format(validate_column(df_original['Experience'].unique().tolist(), 'Experience')))
Analysing Experience column for unique value [1, 19, 15, 9, 8, 13, 27, 24, 10, 39, 5, 23, 32, 41, 30, 14, 18, 21, 28, 31, 11, 16, 20, 35, 6, 25, 7, 12, 26, 37, 17, 2, 36, 29, 3, 22, -1, 34, 0, 38, 40, 33, 4, -2, 42, -3, 43]
Is Experience column valid True
1print("Is Income column valid {}".format(validate_column(df_original['Income'].unique().tolist(), 'Income')))
Analysing Income column for unique value [49, 34, 11, 100, 45, 29, 72, 22, 81, 180, 105, 114, 40, 112, 130, 193, 21, 25, 63, 62, 43, 152, 83, 158, 48, 119, 35, 41, 18, 50, 121, 71, 141, 80, 84, 60, 132, 104, 52, 194, 8, 131, 190, 44, 139, 93, 188, 39, 125, 32, 20, 115, 69, 85, 135, 12, 133, 19, 82, 109, 42, 78, 51, 113, 118, 64, 161, 94, 15, 74, 30, 38, 9, 92, 61, 73, 70, 149, 98, 128, 31, 58, 54, 124, 163, 24, 79, 134, 23, 13, 138, 171, 168, 65, 10, 148, 159, 169, 144, 165, 59, 68, 91, 172, 55, 155, 53, 89, 28, 75, 170, 120, 99, 111, 33, 129, 122, 150, 195, 110, 101, 191, 140, 153, 173, 174, 90, 179, 145, 200, 183, 182, 88, 160, 205, 164, 14, 175, 103, 108, 185, 204, 154, 102, 192, 202, 162, 142, 95, 184, 181, 143, 123, 178, 198, 201, 203, 189, 151, 199, 224, 218]
Is Income column valid True
1print("Is ZIP Code colum valid {}".format(validate_column(df_original['ZIP Code'].unique().tolist(), 'ZIP Code')))
Analysing ZIP Code column for unique value [91107, 90089, 94720, 94112, 91330, 92121, 91711, 93943, 93023, 94710, 90277, 93106, 94920, 91741, 95054, 95010, 94305, 91604, 94015, 90095, 91320, 95521, 95064, 90064, 94539, 94104, 94117, 94801, 94035, 92647, 95814, 94114, 94115, 92672, 94122, 90019, 95616, 94065, 95014, 91380, 95747, 92373, 92093, 94005, 90245, 95819, 94022, 90404, 93407, 94523, 90024, 91360, 95670, 95123, 90045, 91335, 93907, 92007, 94606, 94611, 94901, 92220, 93305, 95134, 94612, 92507, 91730, 94501, 94303, 94105, 94550, 92612, 95617, 92374, 94080, 94608, 93555, 93311, 94704, 92717, 92037, 95136, 94542, 94143, 91775, 92703, 92354, 92024, 92831, 92833, 94304, 90057, 92130, 91301, 92096, 92646, 92182, 92131, 93720, 90840, 95035, 93010, 94928, 95831, 91770, 90007, 94102, 91423, 93955, 94107, 92834, 93117, 94551, 94596, 94025, 94545, 95053, 90036, 91125, 95120, 94706, 95827, 90503, 90250, 95817, 95503, 93111, 94132, 95818, 91942, 90401, 93524, 95133, 92173, 94043, 92521, 92122, 93118, 92697, 94577, 91345, 94123, 92152, 91355, 94609, 94306, 96150, 94110, 94707, 91326, 90291, 92807, 95051, 94085, 92677, 92614, 92626, 94583, 92103, 92691, 92407, 90504, 94002, 95039, 94063, 94923, 95023, 90058, 92126, 94118, 90029, 92806, 94806, 92110, 94536, 90623, 92069, 92843, 92120, 95605, 90740, 91207, 95929, 93437, 90630, 90034, 90266, 95630, 93657, 92038, 91304, 92606, 92192, 90745, 95060, 94301, 92692, 92101, 94610, 90254, 94590, 92028, 92054, 92029, 93105, 91941, 92346, 94402, 94618, 94904, 9307, 95482, 91709, 91311, 94509, 92866, 91745, 94111, 94309, 90073, 92333, 90505, 94998, 94086, 94709, 95825, 90509, 93108, 94588, 91706, 92109, 92068, 95841, 92123, 91342, 90232, 92634, 91006, 91768, 90028, 92008, 95112, 92154, 92115, 92177, 90640, 94607, 92780, 90009, 92518, 91007, 93014, 94024, 90027, 95207, 90717, 94534, 94010, 91614, 94234, 90210, 95020, 92870, 92124, 90049, 94521, 95678, 95045, 92653, 92821, 90025, 92835, 91910, 94701, 91129, 90071, 96651, 94960, 91902, 90033, 95621, 90037, 90005, 93940, 91109, 93009, 93561, 95126, 94109, 93107, 94591, 92251, 92648, 92709, 91754, 92009, 96064, 91103, 91030, 90066, 95403, 91016, 95348, 91950, 95822, 94538, 92056, 93063, 91040, 92661, 94061, 95758, 96091, 94066, 94939, 95138, 95762, 92064, 94708, 92106, 92116, 91302, 90048, 90405, 92325, 91116, 92868, 90638, 90747, 93611, 95833, 91605, 92675, 90650, 95820, 90018, 93711, 95973, 92886, 95812, 91203, 91105, 95008, 90016, 90035, 92129, 90720, 94949, 90041, 95003, 95192, 91101, 94126, 90230, 93101, 91365, 91367, 91763, 92660, 92104, 91361, 90011, 90032, 95354, 94546, 92673, 95741, 95351, 92399, 90274, 94087, 90044, 94131, 94124, 95032, 90212, 93109, 94019, 95828, 90086, 94555, 93033, 93022, 91343, 91911, 94803, 94553, 95211, 90304, 92084, 90601, 92704, 92350, 94705, 93401, 90502, 94571, 95070, 92735, 95037, 95135, 94028, 96003, 91024, 90065, 95405, 95370, 93727, 92867, 95821, 94566, 95125, 94526, 94604, 96008, 93065, 96001, 95006, 90639, 92630, 95307, 91801, 94302, 91710, 93950, 90059, 94108, 94558, 93933, 92161, 94507, 94575, 95449, 93403, 93460, 95005, 93302, 94040, 91401, 95816, 92624, 95131, 94965, 91784, 91765, 90280, 95422, 95518, 95193, 92694, 90275, 90272, 91791, 92705, 91773, 93003, 90755, 96145, 94703, 96094, 95842, 94116, 90068, 94970, 90813, 94404, 94598]
Is ZIP Code colum valid True
1print("Is Family colum valid {}".format(validate_column(df_original['Family'].unique().tolist(), 'Family')))
Analysing Family column for unique value [4, 3, 1, 2]
Is Family colum valid True
1print("Is CCAvg colum valid {}".format(validate_column(df_original['CCAvg'].unique().tolist(), 'CCAvg')))
Analysing CCAvg column for unique value [1.6, 1.5, 1.0, 2.7, 0.4, 0.3, 0.6, 8.9, 2.4, 0.1, 3.8, 2.5, 2.0, 4.7, 8.1, 0.5, 0.9, 1.2, 0.7, 3.9, 0.2, 2.2, 3.3, 1.8, 2.9, 1.4, 5.0, 2.3, 1.1, 5.7, 4.5, 2.1, 8.0, 1.7, 0.0, 2.8, 3.5, 4.0, 2.6, 1.3, 5.6, 5.2, 3.0, 4.6, 3.6, 7.2, 1.75, 7.4, 2.67, 7.5, 6.5, 7.8, 7.9, 4.1, 1.9, 4.3, 6.8, 5.1, 3.1, 0.8, 3.7, 6.2, 0.75, 2.33, 4.9, 0.67, 3.2, 5.5, 6.9, 4.33, 7.3, 4.2, 4.4, 6.1, 6.33, 6.6, 5.3, 3.4, 7.0, 6.3, 8.3, 6.0, 1.67, 8.6, 7.6, 6.4, 10.0, 5.9, 5.4, 8.8, 1.33, 9.0, 6.7, 4.25, 6.67, 5.8, 4.8, 3.25, 5.67, 8.5, 4.75, 4.67, 3.67, 8.2, 3.33, 5.33, 9.3, 2.75]
Is CCAvg colum valid True
1print("Is Education colum valid {}".format(validate_column(df_original['Education'].unique().tolist(), 'Education')))
Analysing Education column for unique value [1, 2, 3]
Is Education colum valid True
1print("Is Mortgage colum valid {}".format(validate_column(df_original['Mortgage'].unique().tolist(), 'Mortgage')))
Analysing Mortgage column for unique value [0, 155, 104, 134, 111, 260, 163, 159, 97, 122, 193, 198, 285, 412, 153, 211, 207, 240, 455, 112, 336, 132, 118, 174, 126, 236, 166, 136, 309, 103, 366, 101, 251, 276, 161, 149, 188, 116, 135, 244, 164, 81, 315, 140, 95, 89, 90, 105, 100, 282, 209, 249, 91, 98, 145, 150, 169, 280, 99, 78, 264, 113, 117, 325, 121, 138, 77, 158, 109, 131, 391, 88, 129, 196, 617, 123, 167, 190, 248, 82, 402, 360, 392, 185, 419, 270, 148, 466, 175, 147, 220, 133, 182, 290, 125, 124, 224, 141, 119, 139, 115, 458, 172, 156, 547, 470, 304, 221, 108, 179, 271, 378, 176, 76, 314, 87, 203, 180, 230, 137, 152, 485, 300, 272, 144, 94, 208, 275, 83, 218, 327, 322, 205, 227, 239, 85, 160, 364, 449, 75, 107, 92, 187, 355, 106, 587, 214, 307, 263, 310, 127, 252, 170, 265, 177, 305, 372, 79, 301, 232, 289, 212, 250, 84, 130, 303, 256, 259, 204, 524, 157, 231, 287, 247, 333, 229, 357, 361, 294, 86, 329, 142, 184, 442, 233, 215, 394, 475, 197, 228, 297, 128, 241, 437, 178, 428, 162, 234, 257, 219, 337, 382, 397, 181, 120, 380, 200, 433, 222, 483, 154, 171, 146, 110, 201, 277, 268, 237, 102, 93, 354, 195, 194, 238, 226, 318, 342, 266, 114, 245, 341, 421, 359, 565, 319, 151, 267, 601, 567, 352, 284, 199, 80, 334, 389, 186, 246, 589, 242, 143, 323, 535, 293, 398, 343, 255, 311, 446, 223, 262, 422, 192, 217, 168, 299, 505, 400, 165, 183, 326, 298, 569, 374, 216, 191, 408, 406, 452, 432, 312, 477, 396, 582, 358, 213, 467, 331, 295, 235, 635, 385, 328, 522, 496, 415, 461, 344, 206, 368, 321, 296, 373, 292, 383, 427, 189, 202, 96, 429, 431, 286, 508, 210, 416, 553, 403, 225, 500, 313, 410, 273, 381, 330, 345, 253, 258, 351, 353, 308, 278, 464, 509, 243, 173, 481, 281, 306, 577, 302, 405, 571, 581, 550, 283, 612, 590, 541]
Is Mortgage colum valid True
1print("Is Securities Account colum valid {}".format(validate_column(df_original['Securities Account'].unique().tolist(), 'Securities Account')))
Analysing Securities Account column for unique value [1, 0]
Is Securities Account colum valid True
1print("Is CD Account colum valid {}".format(validate_column(df_original['CD Account'].unique().tolist(), 'CD Account')))
Analysing CD Account column for unique value [0, 1]
Is CD Account colum valid True
1print("Is Online colum valid {}".format(validate_column(df_original['Online'].unique().tolist(), 'Online')))
Analysing Online column for unique value [0, 1]
Is Online colum valid True
1print("Is CreditCard colum valid {}".format(validate_column(df_original['CreditCard'].unique().tolist(), 'CreditCard')))
Analysing CreditCard column for unique value [0, 1]
Is CreditCard colum valid True
1
2print("Is Personal Loan colum valid {}".format(validate_column(df_original['Personal Loan'].unique().tolist(), 'Personal Loan')))
Analysing Personal Loan column for unique value [0, 1]
Is Personal Loan colum valid True
Lets Visually inspect distribution of values across each column and check presence of outlier
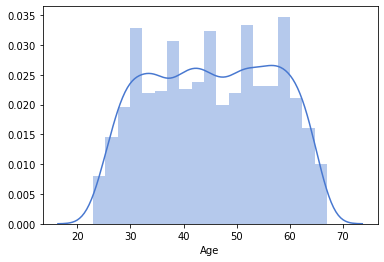
1# Age
2sns.distplot(df_original['Age'],kde=True)
3# Here we conclude that data set is captured for a wide range of age group
<matplotlib.axes._subplots.AxesSubplot at 0x7f68473dc9d0>
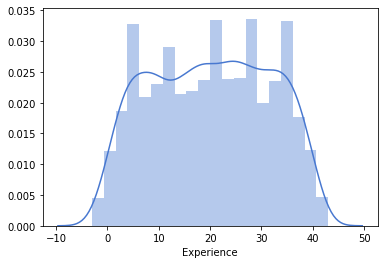
1# Experience
2sns.distplot(df_original['Experience'],kde=True)
3
4#Again here wide range of experience levels
<matplotlib.axes._subplots.AxesSubplot at 0x7f6846b40590>
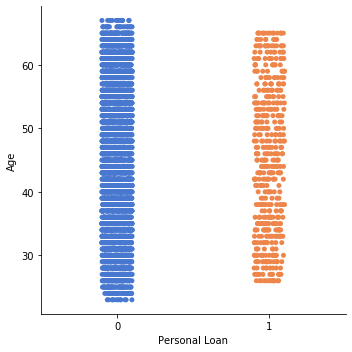
1#Lets Analyse which relation between age and personal load
2
3sns.catplot(y='Age', x='Personal Loan', data=df_original)
4# Except that 0 is more denser than 1 there is no enough visual reference that who would take more loan from this relationship
<seaborn.axisgrid.FacetGrid at 0x7f68473edf10>
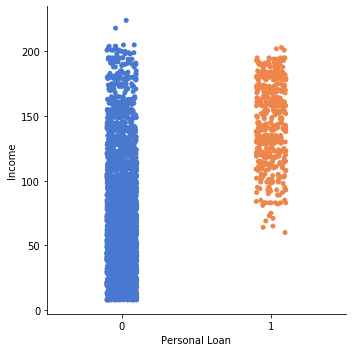
1# Lets try income vs loan
2sns.catplot(y='Income', x='Personal Loan', data=df_original)
3# Quite evident, people whose Income is between 100 and 200 tend to take loan more compared to ones present in lower income.
4# SO field relation to income has proven to have good influence on personal loan, lets see what else fields we have relation to
5print(df_columns)
['ID', 'Age', 'Experience', 'Income', 'ZIP Code', 'Family', 'CCAvg', 'Education', 'Mortgage', 'Personal Loan', 'Securities Account', 'CD Account', 'Online', 'CreditCard']
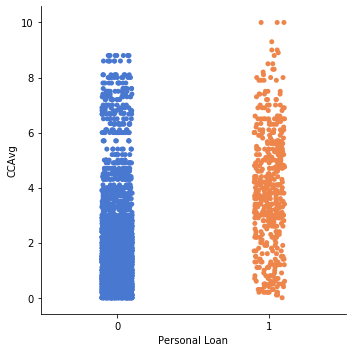
1sns.catplot(y='CCAvg', x='Personal Loan', data=df_original)
2# People whose credit card average is between 2 - 6 seems to have more personal loans
3# that other range as seen from graph below
<seaborn.axisgrid.FacetGrid at 0x7f68469db990>
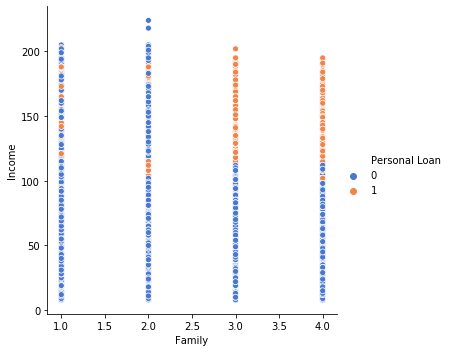
1# One more column we have in our dataset which doesnt corresponds to any income values but is the one which affect it
2# Family can we say that people where more family members are present have takne personal loan
3# sns.relplot(x='Personal Loan', y='Family', data=df_original, fit_reg=False)
4sns.relplot(x="Family", y="Income",hue="Personal Loan", data=df_original);
5
6# We can conclude from this graph that, people who have 3 or 4 family members and whose income is above ~100 to ~200 tend to opt
7# for personal loan more than a different ranges as observed from graph.
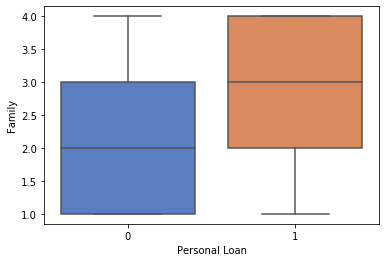
1# Little More exploration using categorical columns
2pd.crosstab(df_original['Personal Loan'],df_original['Family'])
| Family | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Personal Loan | ||||
| 0 | 1365 | 1190 | 877 | 1088 |
| 1 | 107 | 106 | 133 | 134 |
1#Box Plot family and personal loan coparison
2sns.boxplot(y="Family", orient="v", x="Personal Loan", data=df_original)
3# People are from 3-4 most probably these are people, having 1 more children seems to have opeted for personal loan
<matplotlib.axes._subplots.AxesSubplot at 0x7f6846954250>
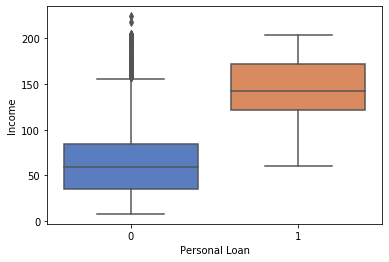
1#Income and Personal Loan
2sns.boxplot(y="Income", orient="v", x="Personal Loan", data=df_original)
<matplotlib.axes._subplots.AxesSubplot at 0x7f68469d6550>
1# Lets Analyse using count plot
2sns.countplot(x='Personal Loan',data=df_original)
3# Even though we have established alot ot relationship between family, age, income, ccavg, income and decided to go further.
4# But the content of our data seem insufficient, we have very few cases of People who have opted for personal loan and
5# More cases of people who have rejected personal loan offer from bank. This imbalance sometimes can affect in model building
6# But in our case this is acceptable, because in real life people who take pl would be less.
<matplotlib.axes._subplots.AxesSubplot at 0x7f6846a85bd0>
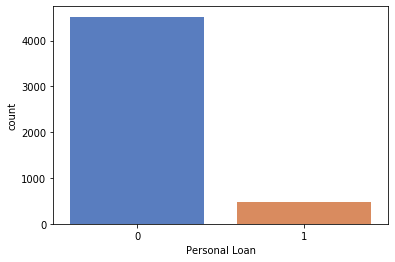
1sns.countplot(x='Education', hue='Personal Loan',data=df_original)
2# From Graph it is evident 3 > 2 >1 where
3# 3: Working, 2: Graduates, 1: Under Graduates
<matplotlib.axes._subplots.AxesSubplot at 0x7f68467da1d0>
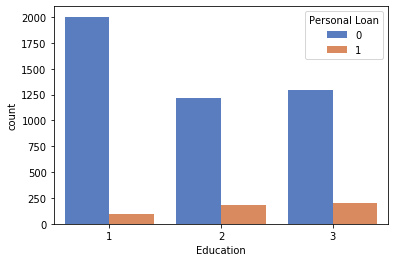
1# Relation between Family& Education to personal load
2sns.barplot('Education','Family',hue='Personal Loan',data=df_original,ci=None)
<matplotlib.axes._subplots.AxesSubplot at 0x7f68467c9310>
1# Classes for all model goes here
2# 1. Class Logistic
3# 2. Class Knn
4# 3. Class NaiveBayes
1# Remember df_main_x will be our main dataframe to be operted on df_original is the unmodified loaded data set which is pure :)
2# seperate data i.e input columns and to be predicted column
3# Drop 'Personal Loan' from dataframe as this is dependent variable and copy it alone in y dataframe
4
5df_main_x = df_original[['Age', 'Experience', 'Income', 'ZIP Code', 'Family', 'CCAvg',
6 'Education', 'Mortgage', 'Securities Account', 'CD Account', 'Online',
7 'CreditCard']]
8
9# Replace all -ve values in experience column to 0
10
11# df_main_x.Experience[df_main_x.Experience.lt(0)] = 0
12
13# df_main_x['Experience'] = df_main_x['Experience'].map(lambda value: value if value >=0 else 0)
14
15df_main_x.loc[df_main_x['Experience']<0, 'Experience']=0
16
17
18print("Experience values unique {}".format(validate_column(df_main_x['Experience'].unique().tolist(), 'Experience')))
19
20df_main_y = df_original['Personal Loan']
21
22
23# Also remember how we removed ID column as it is just a row counter
24
25df_main_x.describe().T
26
27# Now e see that there is no -ve value in experience columns
Analysing Experience column for unique value [1, 19, 15, 9, 8, 13, 27, 24, 10, 39, 5, 23, 32, 41, 30, 14, 18, 21, 28, 31, 11, 16, 20, 35, 6, 25, 7, 12, 26, 37, 17, 2, 36, 29, 3, 22, 0, 34, 38, 40, 33, 4, 42, 43]
Experience values unique True
/home/ashish/installed_apps/anaconda3/lib/python3.7/site-packages/pandas/core/indexing.py:966: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.obj[item] = s
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Age | 5000.0 | 45.338400 | 11.463166 | 23.0 | 35.0 | 45.0 | 55.0 | 67.0 |
| Experience | 5000.0 | 20.119600 | 11.440484 | 0.0 | 10.0 | 20.0 | 30.0 | 43.0 |
| Income | 5000.0 | 73.774200 | 46.033729 | 8.0 | 39.0 | 64.0 | 98.0 | 224.0 |
| ZIP Code | 5000.0 | 93152.503000 | 2121.852197 | 9307.0 | 91911.0 | 93437.0 | 94608.0 | 96651.0 |
| Family | 5000.0 | 2.396400 | 1.147663 | 1.0 | 1.0 | 2.0 | 3.0 | 4.0 |
| CCAvg | 5000.0 | 1.937938 | 1.747659 | 0.0 | 0.7 | 1.5 | 2.5 | 10.0 |
| Education | 5000.0 | 1.881000 | 0.839869 | 1.0 | 1.0 | 2.0 | 3.0 | 3.0 |
| Mortgage | 5000.0 | 56.498800 | 101.713802 | 0.0 | 0.0 | 0.0 | 101.0 | 635.0 |
| Securities Account | 5000.0 | 0.104400 | 0.305809 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| CD Account | 5000.0 | 0.060400 | 0.238250 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| Online | 5000.0 | 0.596800 | 0.490589 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 |
| CreditCard | 5000.0 | 0.294000 | 0.455637 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 |
1# X data frame
2df_main_x.head()
| Age | Experience | Income | ZIP Code | Family | CCAvg | Education | Mortgage | Securities Account | CD Account | Online | CreditCard | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 25 | 1 | 49 | 91107 | 4 | 1.6 | 1 | 0 | 1 | 0 | 0 | 0 |
| 1 | 45 | 19 | 34 | 90089 | 3 | 1.5 | 1 | 0 | 1 | 0 | 0 | 0 |
| 2 | 39 | 15 | 11 | 94720 | 1 | 1.0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 3 | 35 | 9 | 100 | 94112 | 1 | 2.7 | 2 | 0 | 0 | 0 | 0 | 0 |
| 4 | 35 | 8 | 45 | 91330 | 4 | 1.0 | 2 | 0 | 0 | 0 | 0 | 1 |
1# Y Data Frame
2df_main_y.head()
0 0
1 0
2 0
3 0
4 0
Name: Personal Loan, dtype: int64
1# Training constants and general imports
2
3from math import sqrt
4
5from sklearn.linear_model import LogisticRegression
6from sklearn.naive_bayes import GaussianNB
7from sklearn.neighbors import KNeighborsClassifier
8
9from sklearn import metrics
10from sklearn.metrics import classification_report
11
12# taking 70:30 training and test set
13test_size = 0.30
14
15# Random number seeding for reapeatability of the code
16seed = 29 # My BirthDate :)
17
18def isqrt(n):
19 x = n
20 y = (x + 1) // 2
21 while y < x:
22 x = y
23 y = (x + n // x) // 2
24 return x
Logistic Regression
Training General
1# Why are we doing Logistic Regression, because in linear regression response of the system in continuous, where as in
2# logistic regression it is just limited number of possible outcomes i.e in our case [0] or [1] which is whethere a person
3# is likely to take loan or not [yes] or [no]
4
5# Class LogisticRegressionProcess
6from sklearn.model_selection import train_test_split
7
8X_train, X_test, y_train, y_test = train_test_split(df_main_x, df_main_y, test_size=test_size, random_state=seed)
Predicting Logistic Regression
1
2lr_model = LogisticRegression()
3
4lr_model.fit(X_train, y_train)
5
6lr_predict = lr_model.predict(X_test)
7
8lr_score = lr_model.score(X_test, y_test)
Evaluating Logistic Regression
1print("Model Score")
2print(lr_score)
3print("Model confusion matrix")
4print(metrics.confusion_matrix(y_test, lr_predict))
5
6
7print(classification_report(y_test,lr_predict))
Model Score
0.9053333333333333
Model confusion matrix
[[1314 49]
[ 93 44]]
precision recall f1-score support
0 0.93 0.96 0.95 1363
1 0.47 0.32 0.38 137
accuracy 0.91 1500
macro avg 0.70 0.64 0.67 1500
weighted avg 0.89 0.91 0.90 1500
Naive Bayes
Predicting Naive Bayes
1nb_model = GaussianNB()
2
3nb_model.fit(X_train, y_train)
4
5y_nb_predict = nb_model.predict(X_test)
6
7nb_score = nb_model.score(X_test, y_test)
Evaluating Naive Bayes
1print("Model Score")
2print(nb_score)
3print("Model confusion matrix")
4print(metrics.confusion_matrix(y_test, y_nb_predict))
5
6
7print(classification_report(y_test,y_nb_predict))
Model Score
0.876
Model confusion matrix
[[1240 123]
[ 63 74]]
precision recall f1-score support
0 0.95 0.91 0.93 1363
1 0.38 0.54 0.44 137
accuracy 0.88 1500
macro avg 0.66 0.72 0.69 1500
weighted avg 0.90 0.88 0.89 1500
K-NN
Predicting K-NN
1knn_predict = 0
2knn_score = 0
3knn_value = 0
4# We have total 5000 taging
5print(isqrt(df_main_x.shape[0]))
6for i in range(isqrt(df_main_x.shape[0])):
7 kvalue = i+1
8 knn_model = KNeighborsClassifier(n_neighbors=kvalue)
9 knn_model.fit(X_train, y_train)
10 new_knn_predict = knn_model.predict(X_test)
11 new_knn_score = knn_model.score(X_test, y_test)
12 if new_knn_score >= knn_score:
13 knn_score = new_knn_score
14 knn_predict = new_knn_predict
15 knn_value = kvalue
16
17print("Knn evaluation completed, best value is {}".format(knn_value))
70
Knn evaluation completed, best value is 28
Evaluating K-NN
1print("Model Score")
2print(knn_score)
3print("Model confusion matrix")
4print(metrics.confusion_matrix(y_test, knn_predict))
5
6
7print(classification_report(y_test,knn_predict))
Model Score
0.9106666666666666
Model confusion matrix
[[1360 3]
[ 131 6]]
precision recall f1-score support
0 0.91 1.00 0.95 1363
1 0.67 0.04 0.08 137
accuracy 0.91 1500
macro avg 0.79 0.52 0.52 1500
weighted avg 0.89 0.91 0.87 1500
Analysis Result
1
2
3results = {'Logistic Regression': lr_score, 'Naive Bayes': nb_score, 'K-NN': knn_score}
4
5print("Model score are ")
6print(results)
7
8best_score = max(results, key=results.get);
9
10print("Best score is for {} with accuracy {} ".format(best_score, results[best_score]))
11
12if best_score == 'K-NN':
13 print(' with kvalue {}'.format(kvalue))
Model score are
{'Logistic Regression': 0.9053333333333333, 'Naive Bayes': 0.876, 'K-NN': 0.9106666666666666}
Best score is for K-NN with accuracy 0.9106666666666666
with kvalue 70
Analysis Report
Our main aim was to find out people who would accept personal loan based on given data.
From the output we see that K-NN turned out to be the best model with accuracy of 0.91. The other nearest accuracy is 0.90 which is of Logistic Regression. For our use case by identifying the problem state and given the option we had we can consider Logistic Regression to be the best approach, as output to be predicted was 0/1 and that is what logistic regression does, it transforms its output using sigma function. Also,, Logis Regression is parameteric dependent algorithm where as K-NN is not. Theoretically K-NN is a little slower, as we have also seen that to find the best possible k value we had to iterate, this can impact as in our case it is dependent on input data size(row count).
So K-NN Would perform when there is no dependency on time constaints for finding out the best score, where as Logistic Regression would be the optimal choice for time constraints and when the target column is of binary predection asin this case.