How to use logstash with twitter input plugin
Previosuly, we have learnt what is logstash and how to use it with basic standard input example and file as an output with a mutate filter to transform input message to upper cases. In this i will try to explain how we can use inbuilt plugin to stream data from services like twitter and store it into elastic search.
Application Architecture
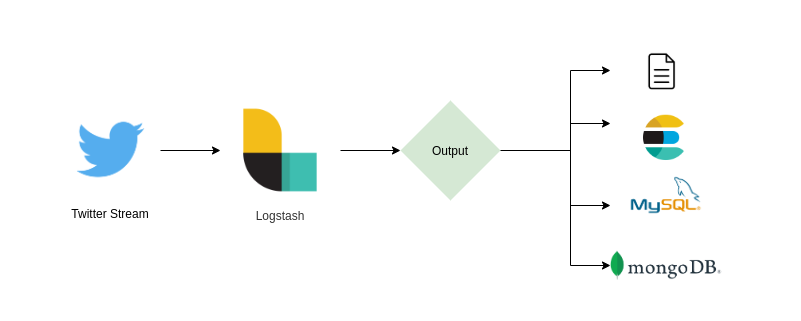
Streaming content from twitter is feed to logstash. Logstash then either applies filter if specified or redirects the output to stdout, file, Elastic Eearch, RDBMS like MySQL, or NoSQL db like mongodb or what is specified in output stage. We already have many output plugins available.
We will configure twitter input plugin with following application credentials:
- key
- secret
- oauth_token
- oauth_secret
All these details will be available from twitter-developer-console. Create an application and gather all the above mentioned keys. Once these details are gathered, put it in a file called .twitter.tokens with content similar to given below, we are setting them as environment variable and we are not shipping them with the application source code. Out logstash conf file will them use environment variable to read these values.
.twitter.tokens
1export TWITTER_KEY=key_value
2export TWITTER_SECRET=secret_value
3export TWITTER_OAUTH_TOKEN=oauth_token_value
4export TWITTER_OAUTH_SECRET=oauth_secret_value
Configure Twtter Input Plugin
Let's get started by configuring twitter input plugin by specifying plugin properties and reading their value from environment variable we exported earlier. Then we will filter necessary fields and redirect output to elastic search server.
twitter-input-logstash.conf
1input {
2 twitter {
3 consumer_key => "${TWITTER_KEY}"
4 consumer_secret => "${TWITTER_SECRET}"
5 oauth_token => "${TWITTER_OAUTH_TOKEN}"
6 oauth_token_secret => "${TWITTER_OAUTH_SECRET}"
7 ignore_retweets => true
8 full_tweet => true
9 keywords=> ["javadevs"]
10 }
11}
12
13output {
14 elasticsearch {
15 hosts => ["localhost:9200"]
16 index => ""javadevs-index
17 }
18}
Start Elastic Search server if is running thorugh standalone folder
1$ ~/projects-drive/installed_softwares/elasticsearch-7.10.1/bin/elasticsearch
Execute .twitter.tokens file such that all environment variable gets initialized
1source .twitter.tokens
Execute logstash command
1logstash -f twitter-input-logstash.conf
Once twitter plugin starts to stream in the data, lets execute some comands on elastic search serve
1curl -X GET http://localhost:9200/java-spring-boot-index/_count -w "\n"
we should get output something similar to this
1{
2 "count": 59,
3 "_shards": {
4 "total": 1,
5 "successful": 1,
6 "skipped": 0,
7 "failed": 0
8 }
9}
If you now execute few search queries on this index let's say execute match-all query
1POST java-spring-boot-index/_search
2{
3 "query": {
4 "match_all": {}
5 }
6}
You will notice that the index is filled with a text key which is the main key for twitter tweet but so many other fields which are not required in our case. In such cases we can apply filter on input data and filter out only things we are interested in.
Alternatively, we can use following query, disadvantage here is that the index still has garbage key-value pairs.
1POST java-spring-boot-index/_search
2{
3 "_source": ["text"],
4 "query": {
5 "match_all": {}
6 }
7}
Let us first delete all the content in the elastic search index by keeping index alive use _delete_by_query
1POST java-spring-boot-index/_delete_by_query
2{
3 "query": {
4 "match_all": {}
5 }
6}
To remove other fields and keep only specific field we are interested in, we shall use inbuilt filter of logstash Prune Filter.
1filter {
2 prune
3 whitelist_names => ["^text$"]
4 }
5}
whitelist_names allows only specified field to pass towards the output channel specified in array.
Entire config files no becomes:
1input {
2 twitter {
3 consumer_key => "${TWITTER_KEY}"
4 consumer_secret => "${TWITTER_SECRET}"
5 oauth_token => "${TWITTER_OAUTH_TOKEN}"
6 oauth_token_secret => "${TWITTER_OAUTH_SECRET}"
7 ignore_retweets => true
8 full_tweet => true
9 keywords=> ["java", "springboot"]
10 }
11}
12
13filter {
14 prune {
15 whitelist_names => ["^text$"]
16 }
17}
18
19output {
20 stdout {}
21 elasticsearch {
22 hosts => ["localhost:9200"]
23 index => "java-spring-boot-index"
24 }
25}
When using logstash always apply filter to keep unwanted data away from getting indexed.
Always remember,
This article covers how to use logstash with twitter-input-plugin.
comments powered by Disqus